今天就接續昨天的內容,來講講我們常用的 LLM 跟去識別化技術的實作過程~
除了以上幾種 LLM 以外,還有一些各自領域常用的模型:
那麼去識別化的過程簡單來說就是,分為以下幾點:
而第一步的模組選擇部分,是依照需求去選擇自己適合的模組,在 Hugging face 的公開平台裡面有非常豐富的開源模型;而當中就有許多 Transformer 函式庫,可以提供我們去免費取用或者 finetune(微調)。
接下來會選擇 Microsoft Presidio 這個 SDK 以及簡單的 Faker package 來測試,來搭配程式簡單跟大家演示去識別化的完成過程。(由於完整程式會比較複雜,所以只會呈現部分程式碼內容、搭配圖片)至於搭配 LLM ai 的部分,後續有機會也會一併分享給大家!


可以去看看 Presidio 有哪些 supported entities 是他們內部支援的 → PII entities supported by Presidio
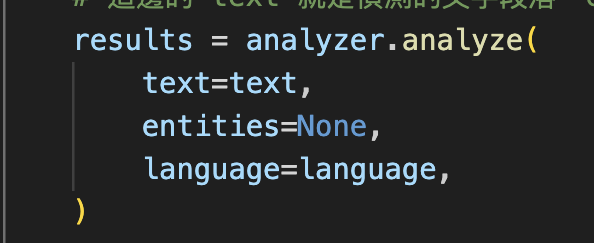
“John’s email is johnpacker@test.com”
“<PERSON>’s email is <EMAIL_ADDRESS>” 而這就是資料的標籤化(也可以算是 → Masking 遮蔽)
每個文字段落重複以上的動作,基本上就完成了去識別化的動作。當然如果還要假名化、資料一般化、假資料替代的話,就是更進階的步驟(簡單來說就是針對每個 entities 去生成、修改成對應 entities 的資料,像是 John → Peter;45 years old → 40-50 years old 等等)。

這樣我們就完成去識別化啦!讚 👍
今天主要專注在去識別化技術的簡單程式範例實作上,雖然沒有 exposed 太多程式碼,因為重點是希望能分享去識別化執行的過程,而不是如何從頭到尾很繁瑣的講述給大家~希望大家理解 >< 那我們明天再見 byebye!👋

